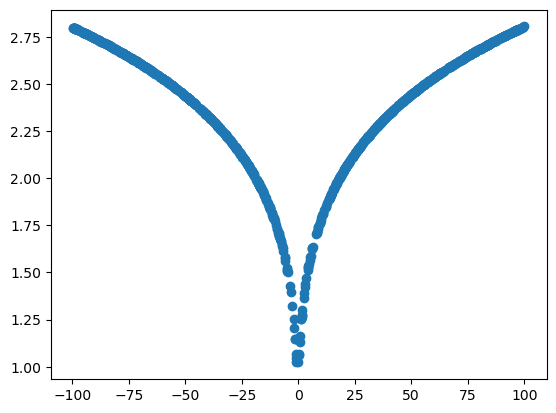

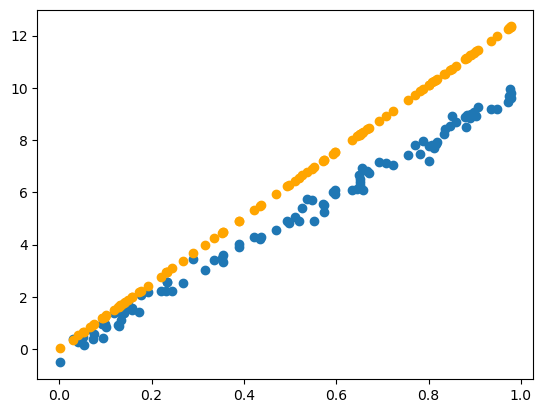
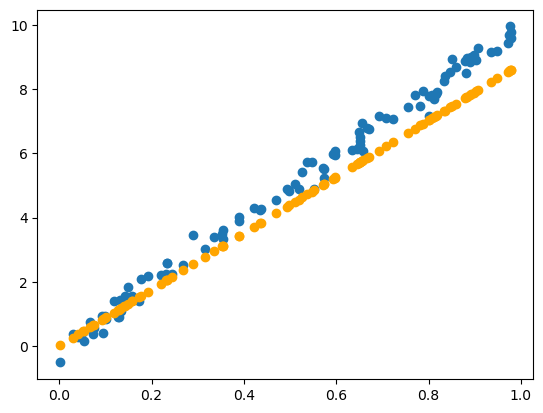
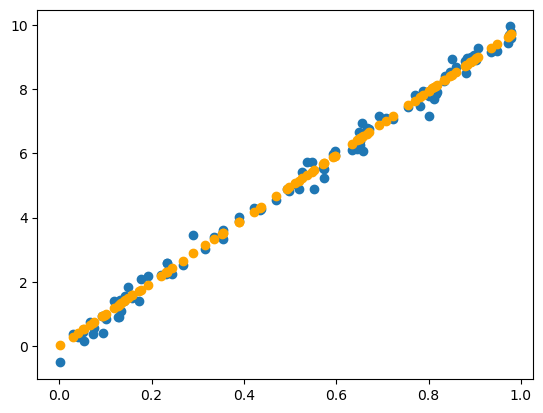
torch.manual_seed(42) # For reproducibility
def unknown_function(x): # We want to approximate it, but assume that we don't know it.
return (3*x**2+2*x+1)**0.1
random_numbers = torch.rand(1000)
input_numbers = random_numbers * 200 - 100 # rescaled between -100 and 100
target_numbers = unknown_function(input_numbers)
plt.scatter(x=input_numbers, y=target_numbers)Main Components
- LinAlg, Statistics, Optimization
- Train neural net with >= 2 layers
- Data represented as tensors