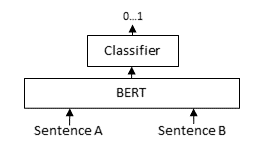
from datasets import load_dataset, DatasetDict
import sentence_transformers
import sentence_transformers.cross_encoder.evaluation
from sentence_transformers import SentenceTransformer, CrossEncoder, InputExample # High-level sentence encoders.
import sentence_transformers.models as models
import sentence_transformers.losses as losses
import torch
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm # Enables progress bars
import pandas as pd
import matplotlib.pyplot as plt
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
QUICK_RUN = False # Config setting to switch between foreground (subset) and background (full-dataset) runningContent
Next, we will look at the content via topic modeling.
We use a recent model called BERTopic (2022).
['A hybrid of genetic algorithm and particle swarm optimization for recurrent network design: An evolutionary recurrent network which automates the design of recurrent neural/fuzzy networks using a new evolutionary learning algorithm is proposed in this paper. This new evolutionary learning algorithm is based on a hybrid of genetic algorithm (GA) and particle swarm optimization (PSO), and is thus called HGAPSO. In HGAPSO, individuals in a new generation are created, not only by crossover and mutation operation as in GA, but also by PSO. The concept of elite strategy is adopted in HGAPSO, where the upper-half of the best-performing individuals in a population are regarded as elites. However, instead of being reproduced directly to the next generation, these elites are first enhanced. The group constituted by the elites is regarded as a swarm, and each elite corresponds to a particle within it. In this regard, the elites are enhanced by PSO, an operation which mimics the maturing phenomenon in nature. These enhanced elites constitute half of the population in the new generation, whereas the other half is generated by performing crossover and mutation operation on these enhanced elites. HGAPSO is applied to recurrent neural/fuzzy network design as follows. For recurrent neural network, a fully connected recurrent neural network is designed and applied to a temporal sequence production problem. For recurrent fuzzy network design, a Takagi-Sugeno-Kang-type recurrent fuzzy network is designed and applied to dynamic plant control. The performance of HGAPSO is compared to both GA and PSO in these recurrent networks design problems, demonstrating its superiority.',
'A Hybrid EP and SQP for Dynamic Economic Dispatch with Nonsmooth Fuel Cost Function: Dynamic economic dispatch (DED) is one of the main functions of power generation operation and control. It determines the optimal settings of generator units with predicted load demand over a certain period of time. The objective is to operate an electric power system most economically while the system is operating within its security limits. This paper proposes a new hybrid methodology for solving DED. The proposed method is developed in such a way that a simple evolutionary programming (EP) is applied as a based level search, which can give a good direction to the optimal global region, and a local search sequential quadratic programming (SQP) is used as a fine tuning to determine the optimal solution at the final. Ten units test system with nonsmooth fuel cost function is used to illustrate the effectiveness of the proposed method compared with those obtained from EP and SQP alone.']